SEO: A rangsorolás alfái és omegái

Egy rövid bekezdés erejéig ismételjük át, hogy mi is a keresőmotorok lényege:
A keresőmotorok folyamatosan szkennelik a teljes internetet, úgynevezett keresőrobotok által. Ezek a robotok mindent felkutatnak, ami nincs előlük direkt elzárva, és mindent, amit arra érdemesnek találnak, bevesznek a saját adatbázisukba, az úgynevezett indexbe.
A Google esetében az indexbe kerülésnek két fő indikátora volt a kezdetek kezdetén:
- Az adott tartalmat egy vagy néhány konkrét kulcsszóhoz relevánsan kötni lehessen,
- illetve minél több link mutasson rá erre a konkrét tartalomra, mert az alapján feltételezik, hogy ez biztosan fontos, hasznos, lényeges és mindenki számára, aki az adott kulcsszavak iránt érdeklődik, érdekes.
Miért ennyire fontosak a tartalomra mutató linkek?
A Google két alapító fenegyereke is ismerte azt a kifejezést, ami a tudományos munkáknál már régóta elterjedt volt, és amit úgy hívunk, hogy citációs index. (Forrás: https://hu.wikipedia.org/wiki/A_tudom%C3%A1nyos_teljes%C3%ADtm%C3%A9ny_m%C3%A9r%C3%A9se)
A citációs index azt mutatja meg egy-egy tudományos műnél, illetve szerzőnél is, hogy konkrétan hányan idézték saját munkáikban hivatkozási alapként, vagy kapcsolódó, fontos információként az adott mű egy-egy részét. Ebbe még akár az is beleférhet, hogy ellenvéleményt fogalmaznak meg az idézettel szemben, de ugye, hogy az ne pusztába kiáltott szóként hasson, meg kell idézni az eredeti művet és konkrét részeit, hiszen az visszahat a véleményre is fontosság tekintetében.
Minél magasabb a citációs index, annál fontosabb maga a mű a tudományos életben. Persze nemcsak ezt figyelik egy-egy mű kapcsán a tudományos életben, hanem még nagyon sok mindent, de Larry Page és Sergey Brin egy ilyen, citációs indexhez hasonló rendszert képzeltek el a saját keresőjük alapvető tudományaként. Ezt adták el a befektetőknek is nóvumként, és ezzel az alapvetéssel is indították a munkát. Úgy tekintettek a linkekre, mint kívülről jövő pozitív szavazatokként arra az oldalra, amire mutattak. Ha egyetlen link sem mutatott egy oldalra vagy domainre, az a Google számára azt jelentette, hogy senki nem szavazott bizalmat az adott oldalnak, és ez bizony nagyon-nagyon rossz jelnek lett tekintve általuk.
Kulcsszó és bejövő linkek száma. Ez volt az alfája és omegája a Google keresőnek.
Más keresők kizárólag tartalom alapján próbáltak keresgélni – szintén robotos, előre feltérképezős, indexelős módszerrel -, és a linkek számát nem vették bele a pakliba, vagy ha mégis, akkor messze nem olyan súllyal, mint a Google.
A Google saját találmánya és világszintű szabadalma lett a linkek számát és minőségét külön jelölő úgynevezett PageRank (avagy oldalrang) nevű algoritmus. Forrás: https://hu.wikipedia.org/wiki/PageRank
De egyáltalán mi a link az interneten?
A link, avagy láncszem az összekötő kapocs az internetes tartalmak között.
Linkkel lehet átugrani egyik oldalról a másikra. Például, a forráshivatkozás a Wikipédia PageRank szócikkére itt pár sorral feljebb, szintén egy link, korábbi nevén hiperlink.
Amikor találsz egy jó cikket, és megosztod az ismerőseiddel a Facebook profilodban, akkor is linkelést használsz. Minden internetes tartalom elérhető egy konkrét linken keresztül, amit úgy is nevezünk, hogy URL.
A link általánosságban azt jelenti, hogy összekötő kapocs, de az URL egy sokkal konkrétabb iránymutatás a látogató, de még a böngésző számára is.
Mi az URL?
A vidirita.com egy domain név.
A https://vidirita.com már egy URL. Ugyanis azon túl, hogy csak néhány karakterrel bővítettük ki a domain nevet, meg a szövegszerkesztő még „alá is húzta” nekünk automatikusan, meg kékre színezte, ez igazából már nemcsak egy információ, hanem egy parancs és iránymutatás is egyben.
A https://vidirita.com a weboldalam főoldalának URL-je.
A https://vidirita.com/onismeret – ez már egy önismereti tanfolyamom URL-je.
Az internetes tartalmakat ezeken a különböző URL-eken lehet elérni. Én úgy szoktam nevezni az URL-t, hogy elérési útvonal.
Gyakorlatilag úgy működik, hogy nemcsak a böngésző, de akár az agyad is tudja az URL alapján, hogy mi hol helyezkedik el az oldalon belül.
Minden tartalomnak külön, egyedi URL-je van az oldalakon belül. A domain a legfőbb iránymutató az agyadnak is, meg a böngészőnek is, amivel meg akarod nyitni a tartalmat, de a domain is több, mint egyszerű elnevezés.
A vidirita.com domainben már két információ van.
A domain neve vidirita.
A domain kiterjesztése, más néven tartománya: .com.
Ha azt írod be a böngészőbe, hogy vidirita.hu, akkor az nem fog működni, mert ilyen oldal nem létezik. (Mivel csak én élek Magyarországon ezzel a névvel, ezért kicsi az esélye, hogy bárki le akarná védetni a vidirita.hu domaint, de ha mégis meg akarná tenni, ahhoz lenne egy-két szavam és megóvnám.)
Annak idején a .com domain lefoglalása tűnt praktikusnak, és azóta is ezt használom.
Ha bármit megváltoztatunk a domainben, akár csak egy betűt is, vagy akár a kiterjesztésben, akkor már nem ugyanahhoz a „házhoz” jutunk el a neten.
A domainek olyanok, mint a házak pontos címei. Nem az van odaírva, hogy Rózsabokor út 1, vagy vidirita út 1, hanem az van odaírva, hogy vidirita.com. De ez csak a látszat: igazából a domain mögött egy IP cím is van, ami a szervert azonosítja, és ami valami ilyesmi formátumú számsor: 85.25.77.86
Ezeket az adatokat a tárhelyszolgáltatónál egy erre kitalált rendszeren keresztül összepasszítják, és akkor fog működni maga a domain az interneten.
Ezekből a közösített, látható és láthatatlan adatokból tudják a böngészők, hogy hová kell menniük konkrétan, mikor meg akarunk nyitni egy weboldalt.
Ha elütöd a címet, akkor máshova visznek. Ha rosszak a beállítások a tárhelyen, akkor nem lehet majd megtalálni az oldaladat. Sok mindennek kell tehát stimmelnie ahhoz, hogy létrejöjjön akár már egy üres fehér lap is az internetes világban. De ma már ezek a dolgok pár perc alatt lezongorázhatóak, és semmiféle extra hozzáértést nem igényelnek, csak azt kell szem előtt tartani, hogy „Nem piszkálunk olyasmihez, amit nem értünk” :).
Térjünk vissza az URL-re: tehát ez az internetes tartalmak elérési útvonala.
Minden fájlnak és mappának külön elérési útvonala van az interneten.
Például:
Van ez a cikkem: https://vidirita.com/az-adomanygyujtes-muveszi-szintje-tanulj-magyarorszag-legsikeresebb-mediaitol-keregetni/
Ebben vannak képek, a legelsőnek ez az elérési útvonala, attól függetlenül, hogy látszik magában a cikkben is, konkrétan ez:
https://vidirita.com/wp-content/uploads/2019/07/444magyarjeti-1.png
{kind=link}
Milyen információkat látunk már szemmel is ebben a linkben, ami a konkrét képhez vezet?
https:// ez ez oldal futtatásának protokollja, az interneten minden vagy http-vel, vagy https-sel kezdődik, ami a nagyközönség számára publikus.
vidirita.com – ez mutatja, hogy melyik domainen belül vagyunk. Ez maga a főkönyvtár az oldalon.
wp-content – ez egy alkönyvtár – közkeletűbb nevén mappa – a domain alá tartozó tárolóhelyen, vagyis tárhelyen, de szoros együttműködésben ezzel a domainnel (egy tárhelyen sok domain lehet egyidejűleg kezelve, de ez felhasználóknak és weboldal tulajdonosoknak csak egy érdekesség, nem kell belemélyedni ennek a technikájába).
uploads – ez egy kis technikai információ egy alkönyvtárról, hogy ez egy kívülről feltöltött elem, például a szerkesztő vagy az író töltötte fel, és nem magának a rendszernek a szerves része (majd erről még beszélünk).
2019 – ez egy alkönyvtár a feltöltött fájlok könyvtárán belül.
07 – szintén alkönyvtár, vagy almappa a 2019-es alkönyvtáron belül. Az alkönyvtárak száma akár végtelen is lehet, de a számítástechnika szereti a 8-as számot (messzire vezetne, hogy miért), ezért 8 alkönyvtáron belülre építkezni már nem annyira szerencsés.
444magyarjeti-1.png – ez már konkrétan a képfájl pontos neve, fájlnévvel a pont előtt, pont, és png a pont után, ami a kiterjesztést jelenti, ami szintén a megjelenítéshez szükséges információ.
Láthatod, hogy egyetlen kép értelmezését mennyire bonyolult leírni. Ez nem a véletlen műve, nem én magyarázok most hosszasan – amúgy szokásom hosszan magyarázni –, ez tényleg ilyen bonyolult, egyetlen tartalmi elem megjelenítése esetén is. És a weboldalak MILLIÓSZÁM tartalmaznak ilyen különálló tartalmi elemeket. Ha nem lenne az URL, nem működne semmi.
Az URL-ek ugyanúgy működnek, mint a fájlok a számítógépeden: ha áthelyezed a fájlt, megváltozik az elérési útvonala, és ha ugyanott akarnád keresni ahol korábban volt, akkor nem találnád, mert már máshogy, más úton kell hozzá eljutni.
Az interneten is, ha áthelyezel egy fájlt, például ezt a képfájlt egy, a 2019-es almappán belül a 07 helyett a 06-ba, akkor ezt a fenti URL-t hiába akarnád megnyitni, úgynevezett 404-es hibát írna ki a böngésző.
A / jelek az url-ben mindig a mappákat választják el egymástól, ezért ISZONYATOSAN fontosak.
A hibás linkek és a 404-es hiba
Számtalanszor megesik, hogy az URL-parancsok kiadásába hiba csúszik, általában elgépelés következtében. Kimarad egy betű, kimarad egy pont, vagy épp egy / jel (perjel).
Ilyenkor az történik, hogy a böngésző próbálja megnyitni az URL-t, de ott nincs semmi. Ezért különböző hibaüzeneteket küld:
Ha például a https://vidirita.com/wp-content/uploads/2019/07/444magyarjeti-1.png
most még helyes linkbe hibákat teszünk, akkor különböző hibaüzeneteket kaphatunk.
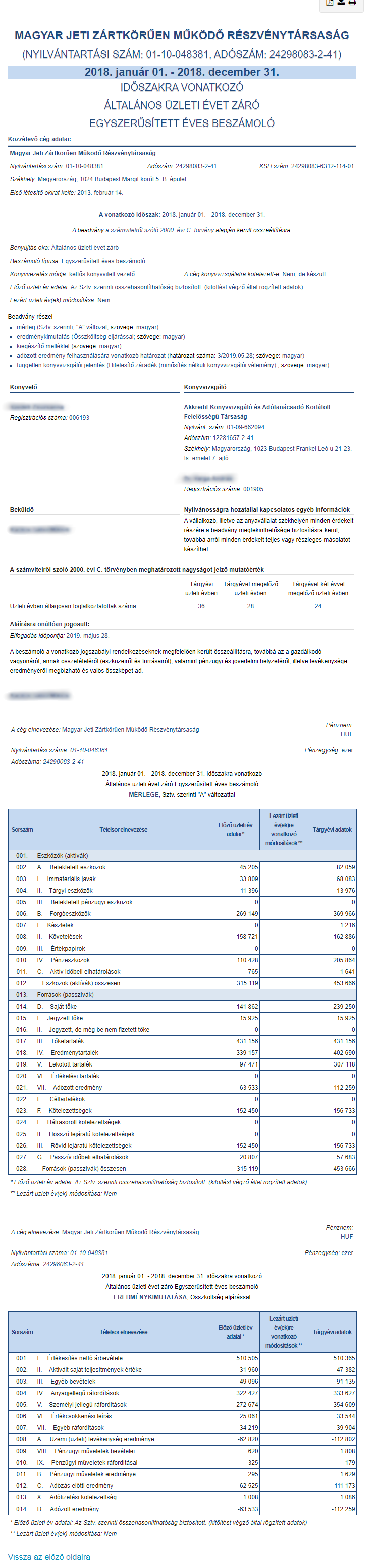
Ha a domainbe, vagyis az egész konkrét rendszerünk főkönyvtárának elérési útvonalába kerül hiba, akkor a következő történik:
https://vidiryta.com/wp-content/uploads/2019/07/444magyarjeti-1.png
{kind=link}
(a vidirita.com-ban átírtam egy i-t y-ra: vidiryta.com)
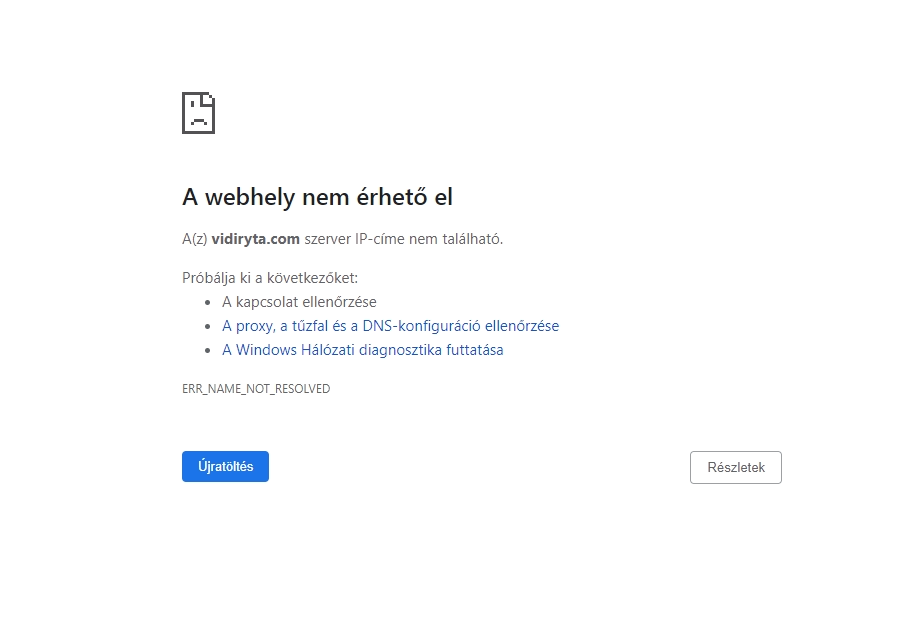
A böngésző alapvetően nem fogja megtalálni az oldalt. Ő keresi a szerver IP címhez tartozó domain nevet, de mivel nem leli, mert nincs ilyen, amiben y van, rögtön jelzi, hogy szerinte mi lehet a probléma.
Persze úgy is el lehet írni domain neveket, hogy valaki más oldalára visz át a böngésző, tehát ilyen esetben nem mindig jelenik meg a hibajelzés, lehetséges, hogy csak eltérítődik a böngésző oda, ahova te pont nem akarnád (pl. a konkurenciához, akinek egy betűnyivel különbözik a domain neve a tiédtől… majd beszélünk még a domain választás szerencsétlenségeiről).
De ha a domain név UTÁN van hiba az url-ben, akkor egészen más üzenetet kapunk.
https://vidirita.com/wp-contet/uploads/2019/07/444magyarjeti-1.png
(a wp-content alkönyvtár nevéből kihagytam egy „n”-t)
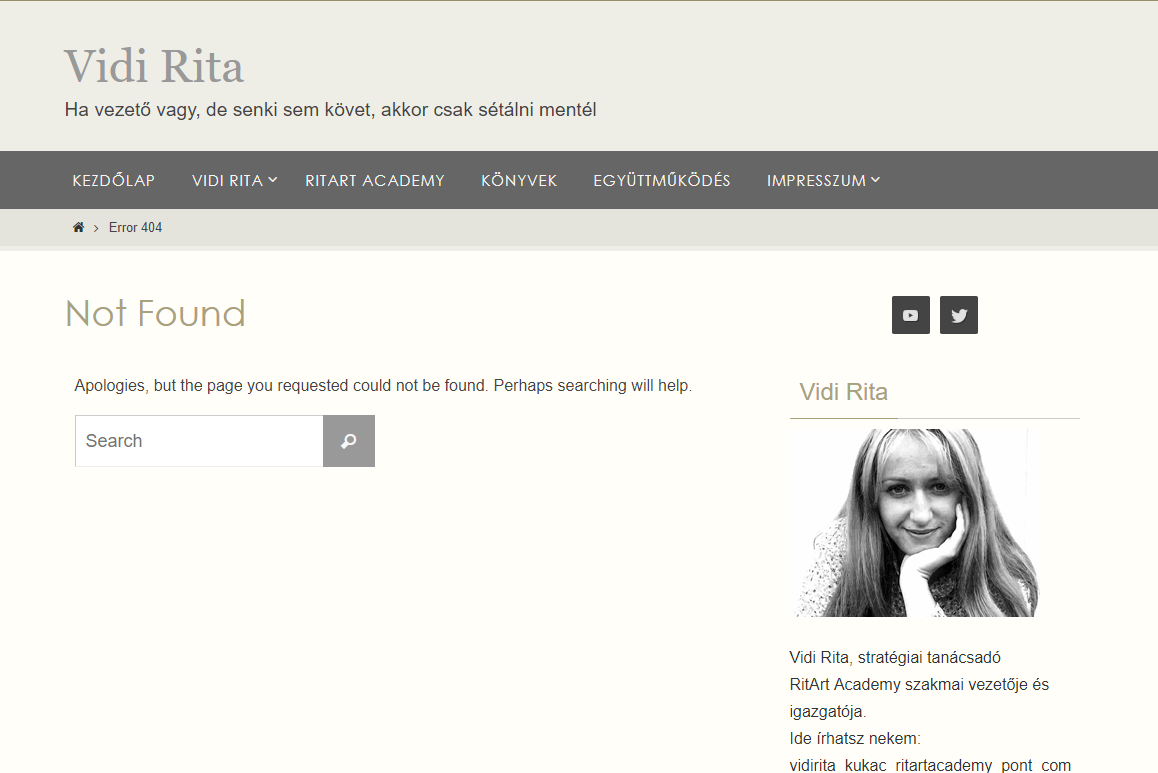
Ekkor a domain tartományon belül keresi a fájlt a böngésző, és mivel nem találja, ezért úgynevezett „404-es” hibát „dob” (a dob az a szleng része :)).
Ilyenkor kiírja, hogy hát bocsi, de nem találtam meg azt, amit kerestél, esetleg keress rá máshogy!
Az változó, hogy a 404-es hibák jelzésénél mit látsz az adott oldalon, az enyémen semmi extrát, de az internet tele van vicces 404-es oldal hibákkal, mert ezt be lehet állítani, hogy a véletlenül rossz linkre kattintó, vagy korábbi, már elavult linket behívó látogatók mit lássanak.
A hosnok.hu oldalamon például nem hibajelzés van, hanem az ingyenes feliratkozási lehetőségek, meg „némi” reklám:
KÉP: hosnok404hiba.png
A Wikipédia így fogalmaz: A 404-es vagy Nem található hibaüzenet egy HTTP válaszkód, ami azt jelzi, hogy a kliens kapcsolatba tudott lépni a szerverrel, de a böngésző által kért állomány nem található. https://hu.wikipedia.org/wiki/404-es_hiba
Miért fontos a linkek épsége és, hogy legyenek linkek (kifelé mutatók is)?
A Google azzal, hogy mindent a bejövő és ránk mutató linkek számára tett fel, túldimenzionálta nemcsak a linkek jelentőségét, de a linkek hibáinak jelentőségét és a hiányzó linkeket is.
Például konkrétan internetes zsákutcának titulálta azokat a HTML alapú weboldalakat (https://hu.wikipedia.org/wiki/HTML) – tehát nem a képfájlokat, amik után már nincs semmi, és ez a természetes –, amikről sehová nem mutat link.
Annak idején egy egyszerű weboldal nem állt másból, mint némi HTML kódból.
Most is abból áll egyébként, csak a „némi” helyett az elképesztően nagy mennyiség inkább a jellemző, továbbá már nemcsak HTML kódok, hanem php kódok, css kódok, javascript kódok és hasonló varázsszavak alkotják a weboldalak háttérrendszerét.
A HTML konkrétan azt jelenti, hogy hiperszöveges jelölőnyelv, tehát ha nincs benne hiperszöveg, más néven LINK, akkor felesleges is egy ilyen bonyolult nyelvet használni, bőven elég egy txt fájl némi szöveggel, és már készen is vagyunk (de az ugyebár ronda és buta is.)
A HTML abban volt új, hogy a sima link helyett, ami így néz ki: tud már ilyet is HTML nyelv. Ezt hívjuk már szöveges linknek.
A Google azt mondta, hogy ha egy ilyen képességű oldalra sem mutat link, meg belőle sem mutat ki link, akkor az úgy egyébként nagyon nem bizalomgerjesztő számukra. Lehet, hogy felveszik az indexbe – tudod, ez az ő végtelen adatkönyvtáruk –, de hogy az alapvetően morcos, mufurc és duzzogó könyvtárosuk nem fogja a látogatók elé tárni az ilyen oldalakat a találati listán, az egyszer biztos.
Amikor a Google már jócskán hírnévre tett szert, akkor a weboldal tulajdonosok és webmesterek azzal szembesültek, hogy irtatlan munka olyan oldalakat készíteni kódokból, amikre mutat is link, meg amikről majd mutat kifelé is link, mert ehhez emberi agymunka is kellett, hogy a weboldalakat felépítő összes fájl elérési útvonalát keresztbe-kasul linkeljék mindenhova, hogy egy jól átjárható weboldal jöjjön létre, ne pedig egy internetes zsákutca.
Tehát nagyon gyorsan eljött az az idő, hogy nemcsak a bejövő linkekkel, meg a kulcsszavas tartalommal kellett foglalkozni, hanem azzal is, hogy a honlap önmagában jól átlinkelt legyen.
Ekkor született meg többedmagával együtt a WordPress, és törte át a belső linknélküliség falát (erről majd lesz még szó).
A linkekkel kapcsolatos problémák tehát:
– Ha a linkek sérültek, az probléma a Google szerint, hiszen hiába vették fel az indexbe a tartalmat, ha nem tudják oda eljuttatni a látogatókat a saját találati listájukból. Így a morcos könyvtáros nem fogja kitenni a keresésekkor a találati listára a kérdéses tartalmat, de egy idő után az indexből is törölni fogja, ami nagyon-nagyon rossz ómen az egész oldal (vagyis domain) számára.
– Ha az oldalról KIFELÉ nem mutat link, az is probléma, mert a Google szerint az egy internetes zsákutca, és onnan csak visszafelé, a találati listára vezet út (hiszen a találati listáról jutott oda a látogató, köszönhetően a Google mindenhatóságának). Mindig gondoskodni kell róla, hogy előre is vigyen az út, ne csak hátra. Ezt a rendszert nevezzük belső linkeknek. (Nagyon fontos fogalom, jegyezd meg!)
– Ha nincsenek az oldalra – akár a domainre, vagy az alkönyvtárakra, konkrét tartalom-URL-ekre mutató külső, bejövő linkek –, az azt jelenti, hogy senki nem szavazott bizalmat a tartalomnak, tehát a Google sem fog. Minél több a bejövő link, annál nagyobb a bizalom a Google szerint.
– Ha a linkek csak csupasz linkek, nem pedig a HTML előnyeit kihasználva szép szöveges linkek, azok a Google szerint gagyik. Ha már létezik a HTML, illik használni – szólt a szentencia, és ezért aztán fel kellett fejlődni a csupasz linkek alkalmazása helyett a szöveges linkelésben is.
Mindezek az alapvetések 1998-ban is éltek, és ma is érvényben vannak.
Csak ezek mellett a korai években ott volt még a KULCSZÓ istensége, ma meg már további kb. 500 tényezőt vesz figyelembe a Google, mind az indexbe kerülésnél, mind a találati listára való felkerülésnél.
Összefoglalva: ahhoz, hogy értsd, mik a SEO alapjai, tudnod kell, mik az URL-ek, mit jelentenek a linkek a sztoriban, miért nem lehetnek hibásak a linkek, és miért nem szabad internetes zsákutcákat létrehozni.
Következő alkalommal folytatjuk a noindex, nofollow, dofollow paranccsal, a fekete, fehér és szürkekalapos SEO tudománnyal, és mindennel, ami ezekkel kapcsolatos – lesz még URL téma is :).
SEO Revolution – ma már forradalmárok kellenek a valódi SEO eredményekhez.
SEO főzőcske, de okosan – SEO anyag 1. rész
S lőn a Google kereső, s lőn az ő hatalma nagy – SEO anyag 2. rész
SEO: A nőfaló és társai – SEO anyag 4. rész
Posted on: 2021-03-05, by : Vidi Rita